캐스트 AI(Cast AI)
애플리케이션 성능 자동화 플랫폼
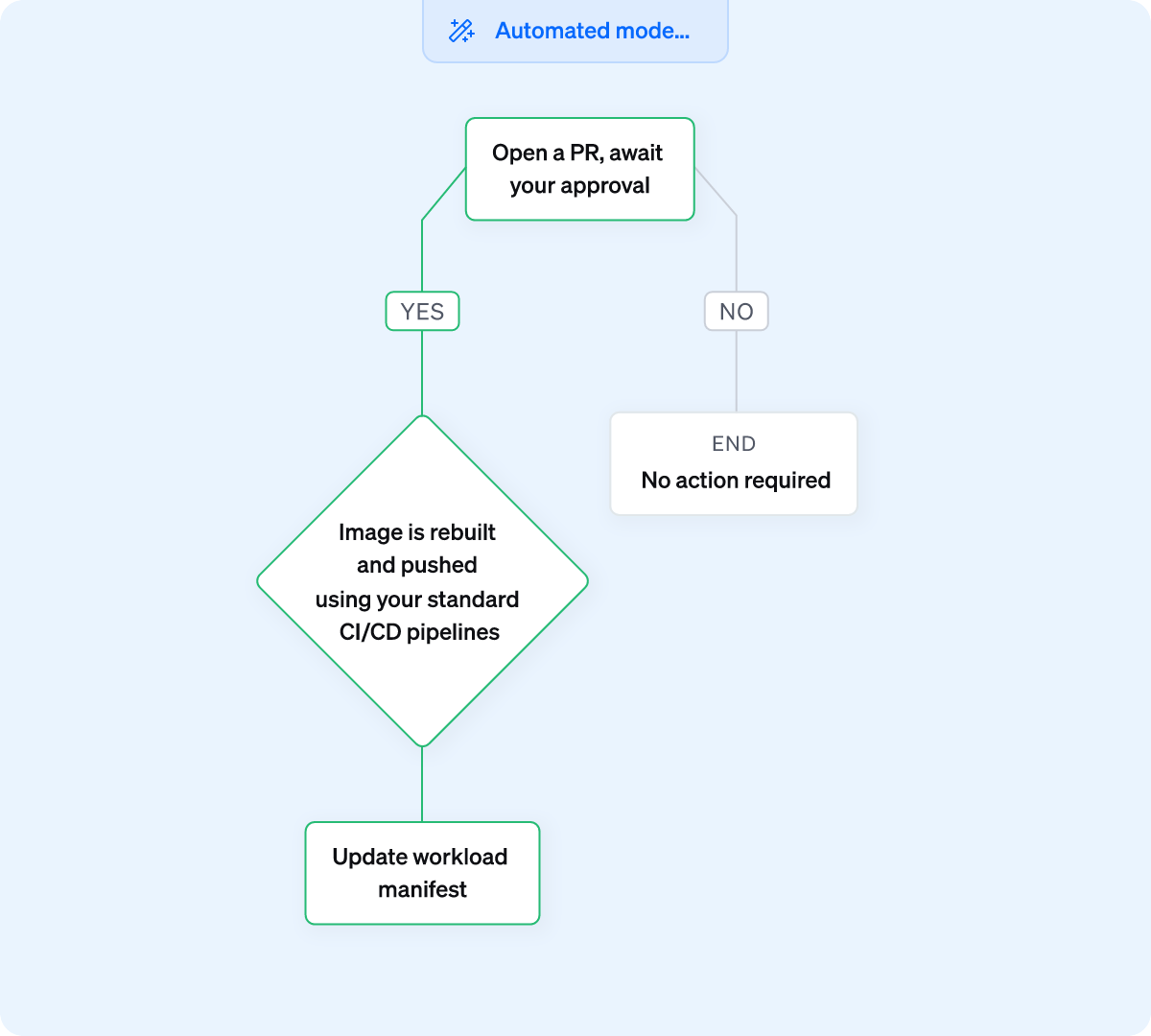
실제 문제를 해결하는 AI 에이전트. 드리프트 수정, 컨테이너 이미지 업데이트, 오류 자동 복구, 정책 시행 등을 수행합니다. 티켓 접수도 필요 없고, 기다릴 필요도 없습니다.
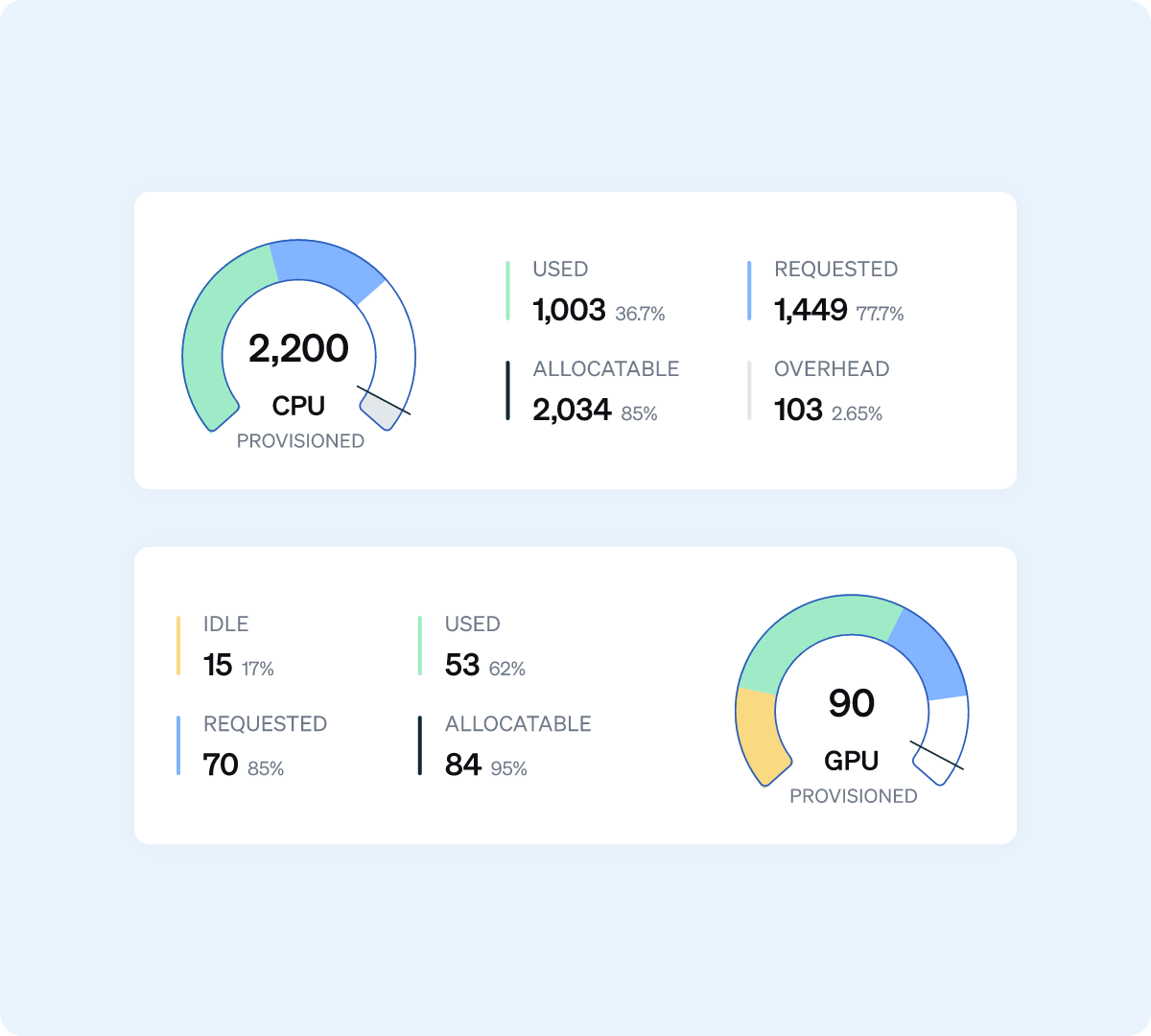
리소스 사용량 및 애플리케이션 성능을 실시간으로 파악하세요. 앱의 동작 방식을 지속적으로 정확하게 파악할 수 있습니다.
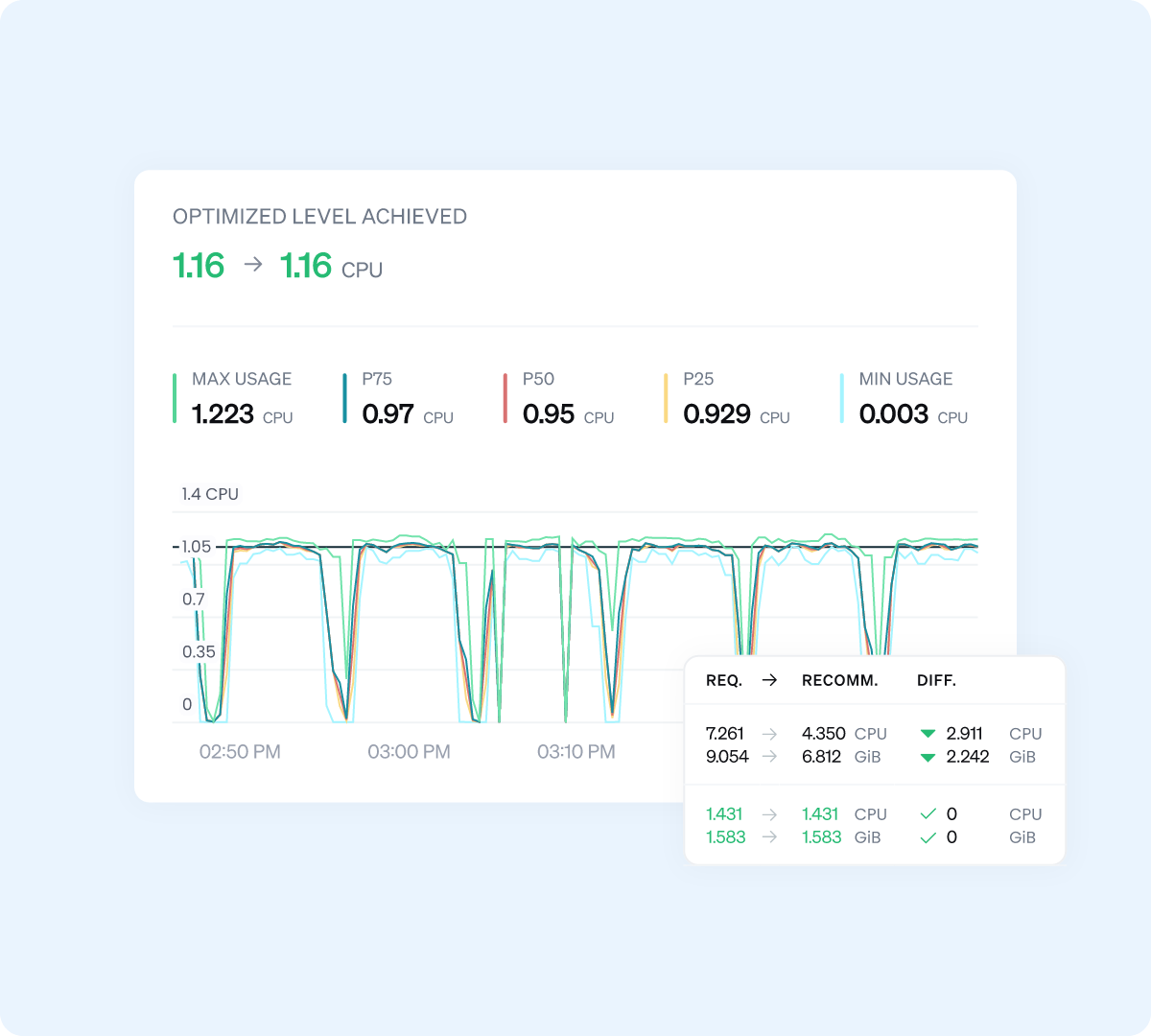
CPU 및 메모리 요청량을 실제 사용량에 맞춰 자동으로 조정합니다. 성능 저하 없이 과잉 프로비저닝을 방지합니다. 모든 워크로드를 지속적으로 최적화합니다.
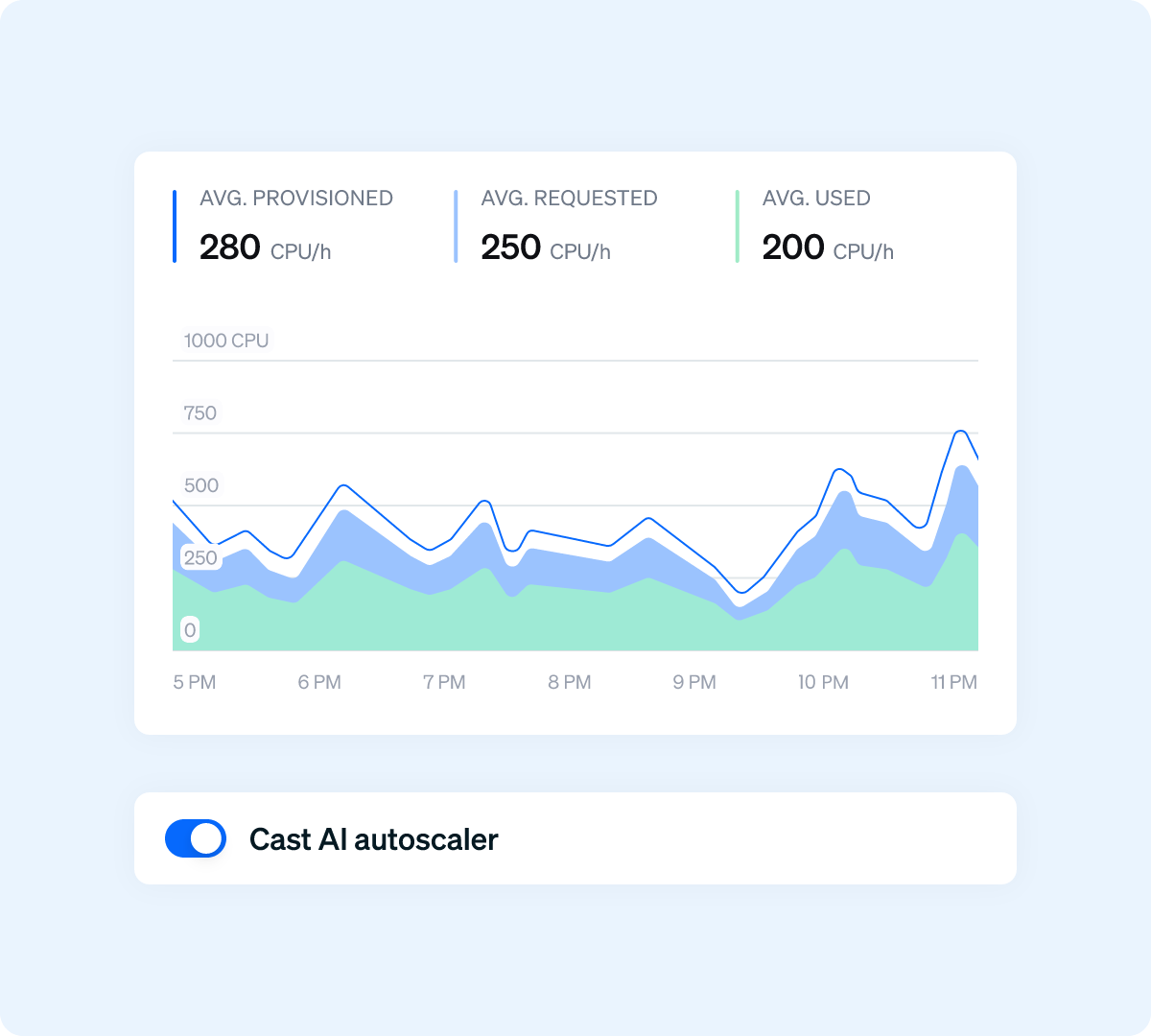
실제 수요에 따라 노드를 확장 및 축소하고, GPU 할당을 최적화하며, 스팟 인스턴스 관리를 자동화하세요. 클라우드 또는 온프레미스 환경 전반에 걸쳐 하나의 컨트롤 플레인을 제공합니다.


클라우드 비용 40~70% 절감 및 엔지니어 생산성을 향상했습니다.
자동화를 통해 Kubernetes 운영 오버헤드와 비용을 절감했습니다.

성능 저하 위험 없이 K8s 워크로드를 자동으로 최적화했습니다.