AI 서비스는 배포 이후가 더 어렵습니다. LLM은 동일한 입력에도 매번 다른 출력을 낼 수 있고, 에이전트·RAG·외부 API가 복잡하게 얽힌 구조에서 문제가 생겼을 때 어디서 발생했는지 찾아내기가 쉽지 않습니다. 프롬프트를 조금 바꿨을 때 전체 서비스 품질에 어떤 영향을 미치는지도 사전에 알 수 없습니다. 이를 해결하기 위해서는 AI 서비스의 내부 동작을 추적하고, 품질을 정량적으로 측정하고, 실험을 통해 지속적으로 개선하는 체계가 필요합니다. 이 글에서는 AI 서비스의 관측(Observability)·평가(Evaluation)·개선(Experimentation & Improvement)을 하나의 플랫폼으로 다루는 Arize AX의 개념과 원리를 설명합니다. Trace와 Span이 무엇인지, LLM as a Judge가 어떻게 작동하는지, 에이전트 개선 사이클이 어떻게 맞물리는지를 중심으로 살펴봅니다.
☑️AI 서비스는 왜 관리하기 어려운가
AI 서비스는 일반 소프트웨어와 다르게 작동합니다. LLM은 동일한 입력에도 매번 다른 출력을 낼 수 있고, 내부 추론 과정이 외부에 드러나지 않습니다. AI가 스스로 만들어낸 데이터의 정확성을 제대로 평가하지 못하고, 검증되지 않은 오류는 시간이 지날수록 복합적으로 증폭됩니다. 특정 포인트에서의 실패가 전체 프로젝트를 무너뜨릴 수 있습니다.
실제로 AI 서비스의 처리 과정은 단순하지 않습니다. 온라인 구매 AI 서비스 하나만 봐도, 사용자 의도를 파악한 뒤 비정형 데이터를 정형으로 변환하고, 검색 API를 호출하고, RAG로 고객 지원 문서를 검색해 답변을 제공하고, 주문 세부정보 API를 호출하고, 프로모션 DB에서 할인 정보를 가져오는 과정이 LLM·API·Application 레이어에 걸쳐 복잡하게 얽혀 있습니다. 이 구조에서 작은 프롬프트 변경 하나가 전체 결과에 어떤 영향을 주는지 사전에 파악하기 어렵고, 문제가 생겼을 때 어디서 발생했는지 찾아내기도 쉽지 않습니다.
☑️그래서 AI Observability가 필요하다
미들웨어에는 Jennifer, DBMS에는 MaxGauge, 클라우드에는 Grafana나 Datadog 같은 전용 모니터링 도구가 있습니다. AI 플랫폼도 마찬가지입니다. AI Task Flow·처리시간·토큰 사용, 입출력 데이터·프롬프트, QA 품질·벡터 연관성·Toxicity 같은 항목은 기존 모니터링 도구로는 측정할 수 없습니다.
AI 서비스에서 AI Observability 수요가 커지는 배경에는 네 가지 이유가 있습니다.
첫째, AI 가시성 부족입니다. 비결정성으로 인해 오류 진단과 설명의 난이도가 높아지고 있습니다. 둘째, 모델의 확산입니다. 예측 ML·비전·LLM이 동시에 운영되는 환경이 늘고 있습니다. 셋째, 진화하는 복잡성입니다. 에이전트·RAG·함수 호출 등 다단계 의존성이 증가하고 있습니다. 넷째, 성능의 저하입니다. 데이터 변동과 재학습 변화에 따라 Drift가 발생합니다. 생성형 AI의 가치는 운영에서 결정됩니다. 관측되지 않으면 개선할 수 없습니다.
AI Observability는 AI 서비스의 구축과 운영 어려움을 세 가지 축으로 풀어내는 개념입니다.
첫째, Observability입니다. 내 애플리케이션에서 무슨 일이 일어나고 있는지, 문제의 근본 원인까지 추적할 수 있는지를 다룹니다. 둘째, Evaluation입니다. 내가 구축한 AI 앱이 내가 정한 기준에 따라 실제로 얼마나 잘 동작하고 있는지를 측정합니다. 셋째, Experimentation & Improvement입니다. 모델·프롬프트·데이터·변수에 따른 성능 변화를 비교하고 최적의 조합을 찾아내는 과정입니다. 이 세 가지가 맞물릴 때 AI 서비스를 관측하고, 평가하고, 개선하는 체계가 만들어집니다.
☑️Arize AX, AI Observability를 구현하는 플랫폼
Arize AX는 AI 서비스의 개발(Develop)부터 테스트(Test), 배포(Deploy), 운영(Operation)까지 전 라이프사이클에서 AI Observability를 구현하는 통합 플랫폼입니다. 2020년 Uber MLOps 팀 출신 멤버들이 공동 창업했으며, Google Agent2Agent(A2A) 프로토콜 공식 파트너이자 NVIDIA 엔터프라이즈 AI 플랫폼 공식 파트너입니다. LangChain·AutoGen·OpenAI·Bedrock·Vertex AI 등 다양한 프레임워크와 LLM 서비스를 지원합니다.
➕Tracing : AI 앱의 동작을 Span 단위로 추적한다
Arize AX는 AI 앱의 동작을 Trace와 Span 단위로 수집하고 시각화합니다.
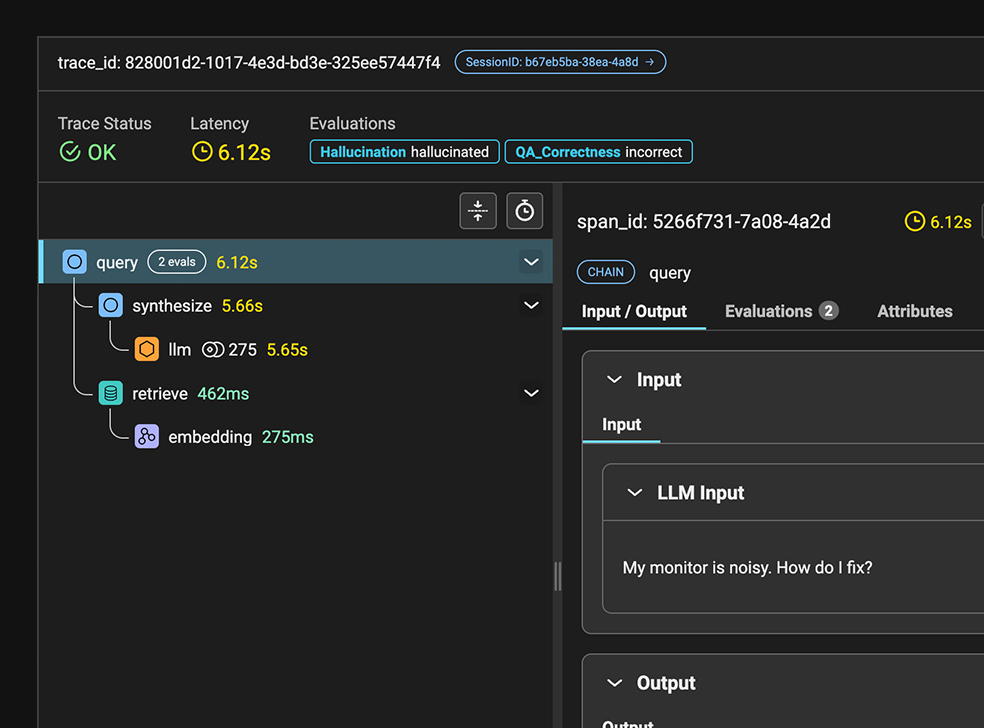
Trace는 하나의 사용자 요청에 대한 전체 흐름을 기록한 단위입니다. 여러 개의 개별 Span으로 구성되며, 애플리케이션 동작 단계별 경로를 보여주어 디버깅과 원인 파악을 가능하게 합니다.
Span은 입력·출력과 시작/종료 시간이 있는 작업 단위입니다. Span의 종류는 다음과 같습니다. LLM은 완성(Completion) 또는 채팅을 위한 LLM 호출이고, Chain은 애플리케이션 단계의 시작점이자 단계 간 연결입니다. Tool은 LLM을 대신해 호출되는 API·함수이고, Agent는 LLM 및 도구 호출 세트를 포함하는 루트 Span입니다. Embedding은 비정형 데이터를 벡터로 인코딩하고, Retriever는 데이터 저장소에서 컨텍스트를 검색하는 질의입니다. Reranker는 관련도 기반으로 문서를 재정렬합니다.
이를 통해 에이전트가 최종 출력에 도달하기 위해 취한 단계, 어떤 도구를 어떤 순서로 사용했는지, 어떤 데이터가 검색에 영향을 미쳤는지, 추론 경로가 어디서 잘못된 방향으로 틀어졌는지를 파악할 수 있습니다. 프롬프트·Retriever·Tool 호출·예외·재시도 등 워크플로우 전 과정이 Span 단위로 추적되며, 지연·에러·토큰 비용을 디버깅할 수 있습니다. OpenTelemetry·OpenInference 기반의 자동·수동 계측을 모두 지원합니다.
➕Evaluation : AI 서비스를 어떻게 평가하는가
AI 서비스의 품질을 측정하는 것은 쉽지 않습니다. Arize AX는 세 가지 방식으로 평가를 지원합니다.
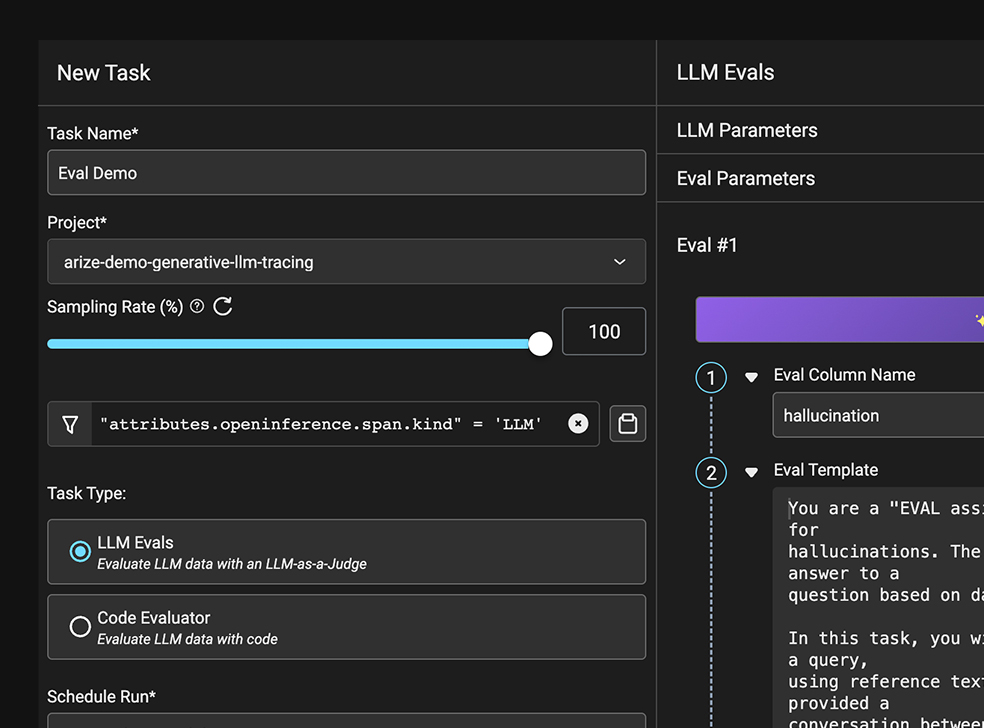
첫 번째는 LLM as a Judge입니다. LLM을 평가자로 활용해 품질을 자동으로 측정하는 방식입니다. 평가 항목별 템플릿을 제공하고 사용자가 커스터마이징할 수 있습니다. Span·변수·데이터를 기반으로 프롬프트를 생성해 LLM을 호출합니다. 두 번째는 Code/Logic Based Evals입니다. 평가 규칙을 코드로 직접 정의하는 방식입니다. 선택한 규칙별 기본 코드를 제공하며, Span·변수·데이터 기반의 로직을 구현하고 코드를 실행합니다. 세 번째는 Annotations입니다. 전문가가 직접 주석을 다는 방식입니다. 평가 타입·라벨링 등을 사전 정의하고, 정의된 주석에 따라 Trace·Span 단위로 평가 값을 입력합니다.
평가 항목 - 무엇을 측정하는가
Arize AX가 측정할 수 있는 평가 항목은 다음과 같습니다.
RAG Flow에서 평가 항목은 어떻게 연결되는가
RAG 기반 AI 서비스에서는 질문, 생성된 답변, 검색된 문맥, Ground Truth 답변 네 가지 데이터가 생성됩니다. 이 데이터들 사이의 관계를 기준으로 다음과 같이 평가 항목이 연결됩니다. Q/A 정확성은 생성된 답변이 실제 정답과 비교했을 때의 정확도를 측정합니다. 답변 관련성은 생성된 답변이 질의에 얼마나 적절한지를 평가합니다. RAG 관련성은 검색된 컨텍스트가 질의에 얼마나 관련성이 있는지를 측정합니다. 근거성·충실도는 검색된 문맥 대비 생성된 답변의 사실적 일관성을 평가합니다. 문맥 재현율은 검색된 컨텍스트가 정답과 일치하는 정도를 측정합니다.
➕Experimentation & Improvement : 어떻게 개선으로 이어지는가
실험이란 프롬프트·모델·데이터·파라미터를 변경했을 때 성능이 어떻게 달라지는지 정량적으로 검증하는 과정입니다. 어떤 변경이 성능에 유의미한 영향을 주는지, 최적의 조합은 무엇인지, 기대 효과 외에 비용 증가·지연·정책 위반·Hallucination 같은 부수 효과는 없는지를 확인합니다.
Golden Dataset은 이 실험의 기준이 되는 검증된 예시 데이터셋입니다. Playground를 통해 프롬프트를 설정하고, LLM as a Judge가 정확도·할루시네이션 등 지표를 자동으로 수치화합니다. 변경 전후 버전을 나란히 비교해 최적의 조합을 찾아낼 수 있습니다.

개선은 에이전트 개선과 평가 개선 두 가지 루프가 맞물려 작동합니다. 에이전트 개선 루프는 데이터 수집, 평가 수행, 실패 사례 수집, 프롬프트 개선·파인튜닝, 학습 데이터셋 생성 순으로 반복됩니다. 평가 개선 루프는 실패 사례 수집, 평가 데이터셋 생성, 평가 프롬프트 개선, 프롬프트 업데이트 순으로 순환합니다. 두 루프는 평가 점수가 낮은 사례를 공유하며 서로 연결됩니다.
Prompts — 프롬프트 실험부터 배포까지 한 화면에서
Prompt Playground에서 템플릿·입력변수·모델·파라미터를 코드 없이 A/B 실험할 수 있고, 데이터셋 기반으로 대량 테스트와 버전별 비교가 가능합니다. 버전 추적·변경 이력 관리·롤백·릴리즈를 통해 일관성을 유지합니다.
Dataset & Annotations — 평가 신뢰도를 높이는 방법
Trace에 수동 라벨을 추가해 정답·오류 유형·품질 메모를 기록하고, Golden Dataset을 생성합니다. LLM 평가와 사람 라벨의 불일치 사례를 자동으로 탐색해 Experiments에 활용합니다.
➕운영 단계에서 무엇을 감시해야 하는가
AI 서비스를 운영하다 보면 데이터 변동이나 재학습 변화에 따라 모델 성능이 저하되는 Drift가 발생합니다. Arize AX는 에러율·토큰 사용량·응답 지연 시간(Latency)을 실시간으로 추적합니다. 구조화 데이터(PSI)와 비구조화 데이터(UMAP Embedding)의 분포 변화도 모니터링합니다. 프로덕션 환경에서 수집된 LLM as a Judge 평가 점수를 집계해 온라인 평가 결과를 대시보드에서 확인할 수 있습니다. 임계치를 초과하면 Slack·PagerDuty·OpsGenie와 연동해 알림을 자동으로 발송합니다.
Alyx — AI 코파일럿
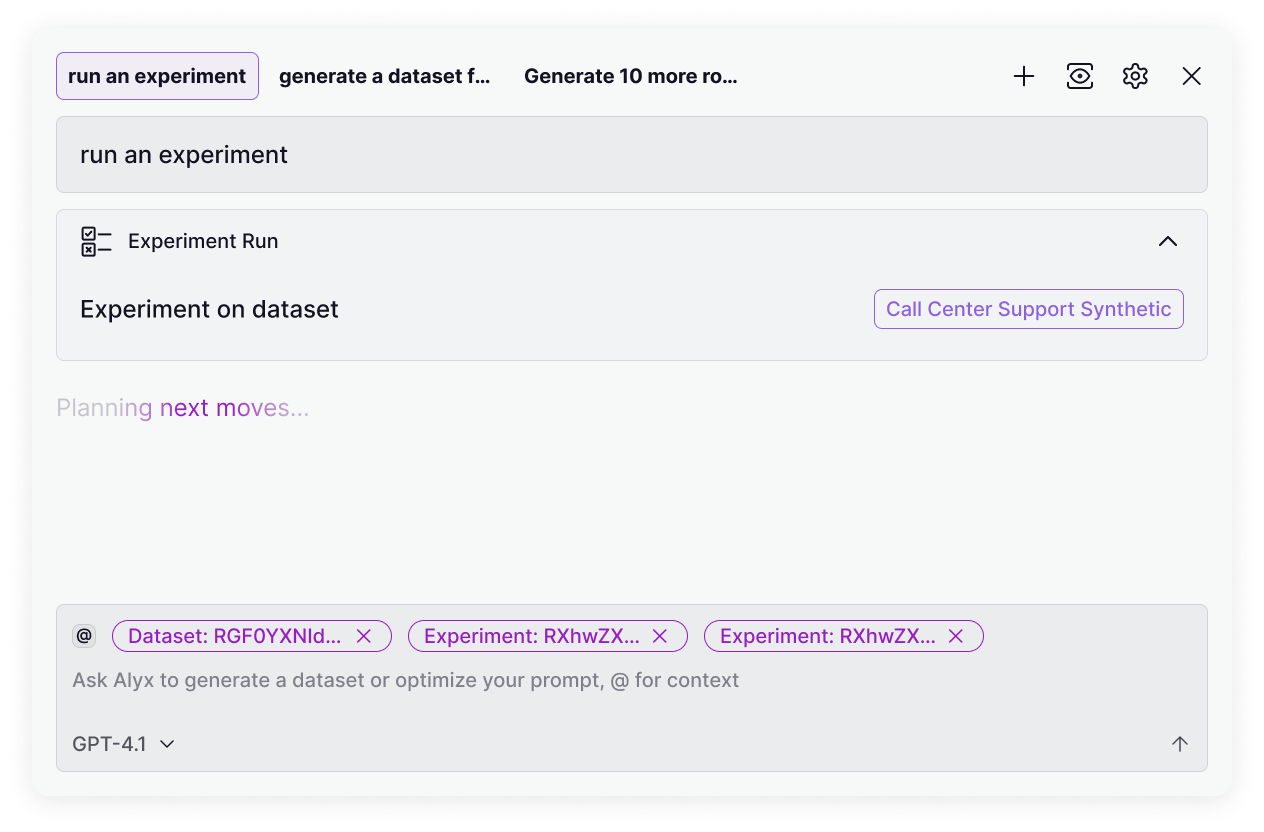
Alyx는 Arize AX 전역에 내장된 AI 코파일럿입니다. Prompts·Dataset·Eval·Dashboard·Trace & Span 데이터를 맥락으로 활용해 30개 이상의 전문 스킬을 기반으로 트레이스 디버깅, 오프라인·온라인 평가 요약, 성능 개선 제안을 채팅 인터페이스에서 즉시 수행합니다.
☑️Arize AX의 차별점
Arize AX는 오픈소스 기반 관측 도구들과 비교했을 때 Performance·User Experience·Stability & Compatibility 세 축에서 차별화됩니다.
Performance 측면에서는 Arize 전용 고성능 DB가 내장되어 있고, 대용량 Trace·Span의 확장성을 지원하며, No-Latency 실시간 자동 Evaluation을 제공합니다. User Experience 측면에서는 End User Analysis가 가능한 Dashboard, Alyx 코파일럿, Monitoring & Alerting을 제공합니다. Stability & Compatibility 측면에서는 SSO·RBAC 기반 인증, Tracing·Span Loss-Zero 및 필터·변형·미러링 연동, LangChain·AutoGen·OpenAI·Bedrock·Vertex AI 등 다양한 프레임워크와의 호환성을 지원합니다.
☑️Arize AX가 필요한 이유
AI 사업의 성패는 AI 서비스를 얼마나 빠르고 효율적으로 구축하고 운영할 수 있느냐에 달려 있습니다. AI 워크플로우 자동화로 빠르게 시장을 점유하고 전문 영역의 에이전트를 최적화한 기업이 앞서가는 반면, 복잡한 프로세스로 인해 빠른 시장 대응에 실패한 기업들은 경쟁에서 뒤처지고 있습니다.
Arize AX는 이 차이를 만드는 세 가지 영역에서 가치를 제공합니다. 첫째, AI 개발 및 테스트 속도를 가속화합니다. 관측과 평가 체계가 갖춰지면 프롬프트 변경과 에이전트 배포에 걸리는 시간이 줄어듭니다. AT&T는 Arize AX 도입 후 프롬프트 변경 시 에이전트 배포 속도를 3배 향상시켰습니다. 둘째, AI 애플리케이션 성능을 향상시킵니다. 무엇이 문제인지 정확히 파악하고 개선할 수 있을 때 서비스 품질이 올라갑니다. Duolingo는 사용자 불편감을 20% 줄였습니다. 셋째, 에이전트의 안전성과 비용을 유지합니다. 실험과 평가 없이 배포된 변경은 예상치 못한 비용 증가나 정책 위반을 일으킬 수 있습니다. Air Canada는 레드팀 활동 생산성을 2배 높였습니다.
AI 서비스를 배포했다면, 그 다음 단계는 그것이 실제로 얼마나 잘 작동하고 있는지 아는 것입니다. 관측되지 않으면 개선할 수 없습니다.
클라우드네트웍스는 Arize AI 공식 파트너로서 Arize AX 도입 컨설팅과 기술 지원을 제공합니다. AI 서비스 품질 관리와 거버넌스 체계 구축에 관심이 있으시면 연락 부탁드립니다.
▶ Arize AI 자세히보기